
If you're on a team that uses Git, you have to create these things called "commits" to make changes to the codebase. To make things more complicated, you have to create "branches" so you can open "pull requests" before "merging" your code. For those that are new to Git, you might find your working directory or pull requests getting into weird, inexplicable states while attempting to do some of these things. If you're experienced with Git, you might know the right commands to get the job done, but do you know what's actually happening under the hood? This article attempts to demystify Git for new and experienced users alike.
What is "Git"?
Git is a version control system that tracks every change that's ever been made to a codebase. Every Git repository has a ".git" directory, which stores every version of every file that has ever been committed. Git refers to these as "objects". There are three types of objects:
Blob objects store a point-in-time snapshot of a single file. The content of this object is the full file (not a diff or a delta).
Tree objects store a point-in-time snapshot of a single directory. You can think of a tree object as a map of names to blob objects (for files) or other tree objects (for subdirectories).
Commit objects store a reference to a tree object, a reference to a parent commit object, and some metadata, such as the commit message and author.
Git also stores what it calls "references" in the .git directory. A reference is more or less just a human-readable name for a commit. Tags and branches, for example, are simply references to a specific commit.
Example Objects
Let's create a repo and make some commits:
% git init .
Initialized empty Git repository in /Users/chris/Desktop/gittemp/.git/
% echo 'hello, world!' > README
% git add README
% git commit -m 'initial commit'
[master (root-commit) 8c93d3d] initial commit
1 file changed, 1 insertion(+)
create mode 100644 README
% echo 'Hello, world!' > README
% git add README
% git commit -m 'capitalization fix'
% git log
commit 8711a423a0a34032b57bb6da11016c50802f765d (HEAD -> master)
Author: Christopher Brown
Date: Fri May 8 21:01:54 2020 -0400
capitalization fix
commit 8c93d3d4ed3b90feb433707f6ea426d9665217c7
Author: Christopher Brown
Date: Fri May 8 21:01:13 2020 -0400
initial commitYour repository now has one ref and six objects:

If Git used JSON, the state of the repo might look like this:
{
"objects": {
"270c611ee72c567bc1b2abec4cbc345bab9f15ba": {
"type": "blob",
"data": "hello, world!\n"
},
"af5626b4a114abcb82d63db7c8082c3c4756e51b": {
"type": "blob",
"data": "Hello, world!\n"
},
"7dd49419807b37a3afd2f040891a64d69abb8df1": {
"type": "tree",
"children": {
"README": {
"mode": "100644",
"hash": "af5626b4a114abcb82d63db7c8082c3c4756e51b"
}
}
},
"98eb6efee4678ed8a537d0de59d5bfcdc7041560": {
"type": "tree",
"children": {
"README": {
"mode": "100644",
"hash": "270c611ee72c567bc1b2abec4cbc345bab9f15ba"
}
}
},
"8711a423a0a34032b57bb6da11016c50802f765d": {
"type": "commit",
"tree": "7dd49419807b37a3afd2f040891a64d69abb8df1",
"parent": "8c93d3d4ed3b90feb433707f6ea426d9665217c7",
"author": "Christopher Brown",
"message": "capitalization fix"
},
"8c93d3d4ed3b90feb433707f6ea426d9665217c7": {
"type": "commit",
"tree": "98eb6efee4678ed8a537d0de59d5bfcdc7041560",
"author": "Christopher Brown",
"message": "initial commit"
}
},
"refs": {
"heads": {
"master": "8711a423a0a34032b57bb6da11016c50802f765d"
}
}
}
Git doesn't use JSON, but you can find all of this in files within the .git directory. For example, you can cat .git/refs/heads/master or git cat-file -p 8c93d3d (object files are encoded, so you have to use git cat-file to view them).
It's important to note that all of these objects are immutable. The objects are referenced by a hash, and that hash changes if any of the object's data changes.
What is a "commit"?
As we've seen, a commit is just an object with two very important things: a complete snapshot of the filesystem and a parent commit. Because each commit has a parent, the commits in a Git repository form a directed graph, and because each commit is immutable, this graph is acyclic. This directed acyclic graph is commonly known as the Git "DAG".
Let's start thinking of Git in terms of the DAG. If we take away everything but the refs and commit objects, the example repository above looks like this in graph form:
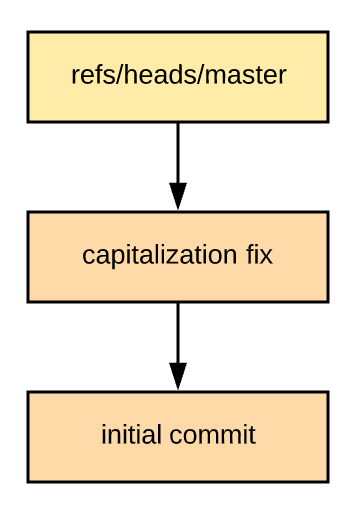
What is a "branch"?
As mentioned above, a branch is simply a reference to a commit. We can create a branch with git checkout -b my-branch. The act of creating the branch just creates a new file in your refs directory, and the content of this file is simply a commit hash. In fact, we could alternatively just cp .git/refs/heads/master .git/refs/heads/my-branch to create this new branch. Now our DAG looks like this:
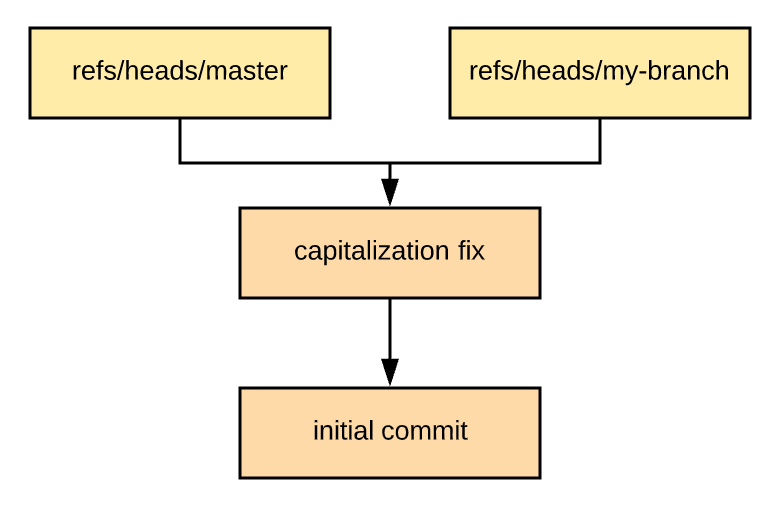
What is a "merge"?
On most teams, before landing your code in the master or development branches, you would create a branch then open a pull request. A reviewer will suggest changes if necessary, then eventually approve it. Once it's approved, you'll need to merge it into the destination branch. Building off of the above example, let's make some changes to the "my-branch" branch:
% git checkout my-branch
Switched to branch 'my-branch'
% echo '# My Repo\n\nHello, world!' > README
% git commit -m 'add header' -a
[my-branch dd5b973] add header
1 file changed, 2 insertions(+)Now the DAG looks like this:
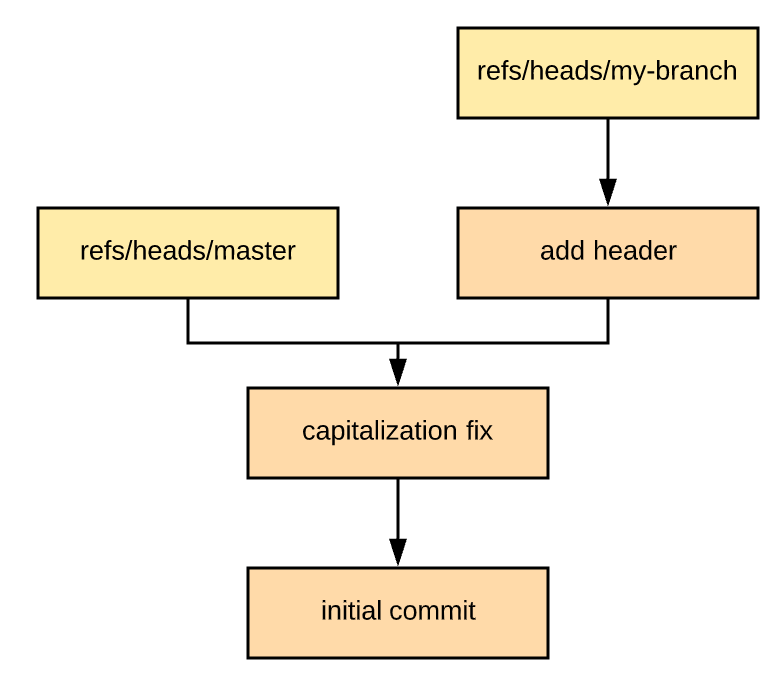
If our pull request were approved and this was merged right away, you might be able to guess what the resulting graph would look like. This would be a "fast forward" merge. In fact, we could merge it by just updating the master ref: cp .git/refs/heads/my-branch .git/refs/heads/master. Easy! (But please don't actually use cp for this!) Unfortunately, this isn't always how things go. Often you might have multiple commits in your branch that you want to squash down to one commit upon merging. Or someone else may have made commits in master since you opened your pull request.
Let's make this a bit more complex by adding an unrelated commit to master:
% git checkout master
Switched to branch 'master'
% echo 'Do whatever.' > LICENSE
% git add LICENSE
% git commit -m 'add license'
[master 2f0378b] add license
1 file changed, 1 insertion(+)
create mode 100644 LICENSENow our DAG looks like this:
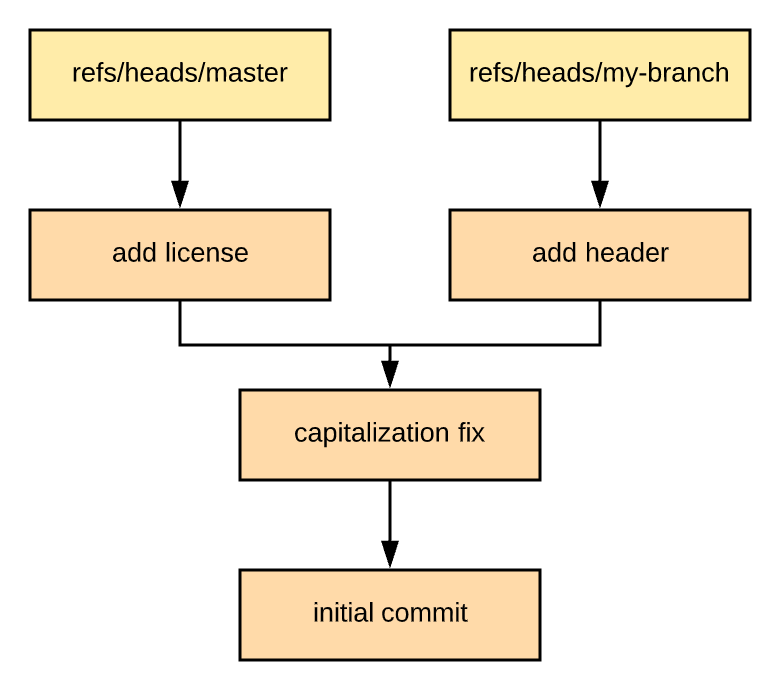
Obviously, we can't do a merge here by just changing a ref. One way to merge this would be to git merge --squash my-branch and then git commit. This effectively creates a new commit on the master branch with the changes introduced in my-branch. That's a fine way to merge these branches, but it isn't super interesting. Another way to merge these branches is to just git merge my-branch. If we do this, something much more interesting happens:
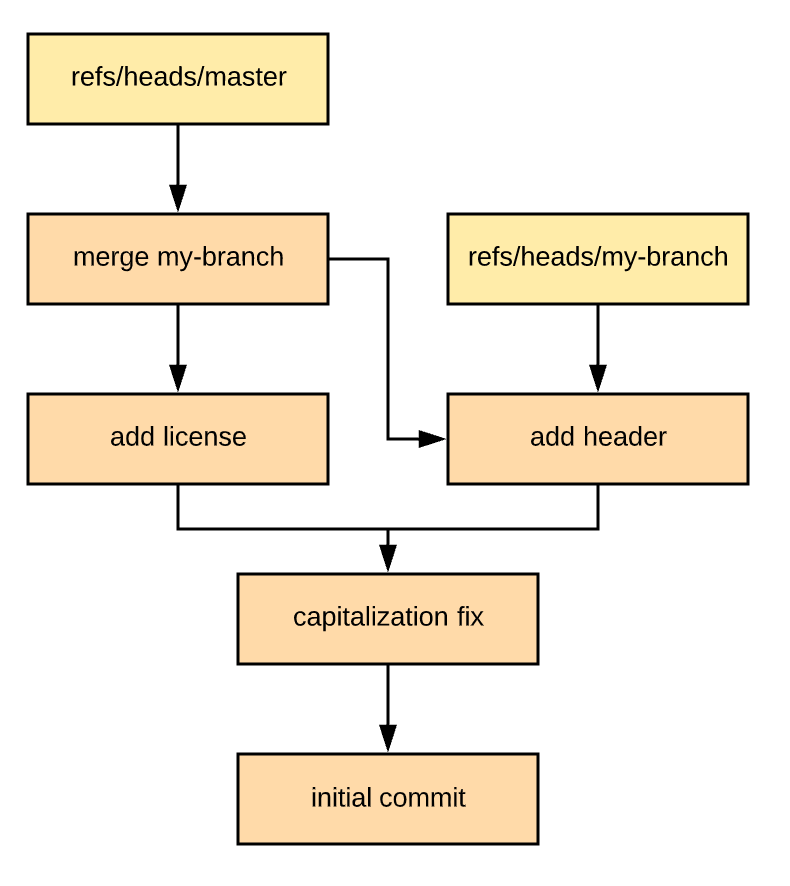
The merge created a new commit on the master branch that has two parents! We can confirm this by inspecting the object file with git cat-file -p HEAD:
tree 1c78ce3bb836b1dfe5095d0e801242daec484334
parent 2f0378b71f5b84a6af12d49772a85b1a53f37e0f
parent dd5b97382393d014061c2f0088a36472843f31cd
author Christopher Brown 1588991147 -0400
committer Christopher Brown 1588991147 -0400
Merge branch 'my-branch'Don't let this intimidate you though; there's nothing particularly magical going on here. The effect is the same as a squash merge except that Git keeps more historical context for the commit.
What is a "rebase"?
Let's say that when you put in your pull request someone made changes to some of the same files in master. In that case, when you try to merge your pull request, you'll get merge conflicts. In this situation, if you were to rebase your branch onto master, it would be as if your branch were created after all of the changes to master.
Let's rewind and say that instead of adding a LICENSE to master, someone else also adds a header to the README:
% git checkout my-branch && git reset --hard dd5b973
% git checkout master && git reset --hard 8711a42
% echo '# The Repo\n\nHello, world!' > README
% git commit -m 'add header' -a
[master 6f249b4] add header
1 file changed, 2 insertions(+)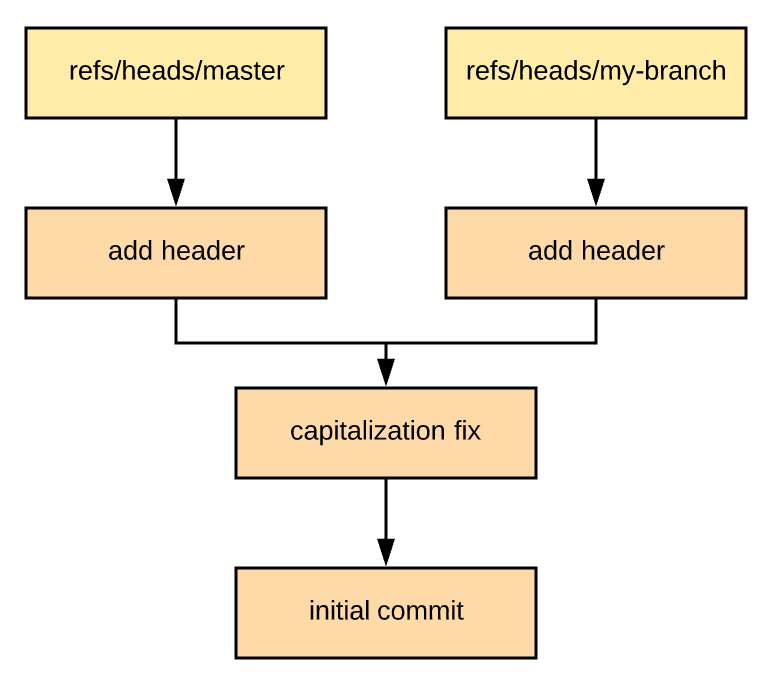
If we try to merge this in, we'll get a conflict:
% git checkout master && git merge my-branch
Auto-merging README
CONFLICT (content): Merge conflict in README
Automatic merge failed; fix conflicts and then commit the result.GitHub won't let you merge a Pull Request like this unless you resolve the conflict. One way to do this is to rebase it:
% git checkout my-branch && git rebase master
First, rewinding head to replay your work on top of it...
Applying: add header
Using index info to reconstruct a base tree...
M README
Falling back to patching base and 3-way merge...
Auto-merging README
CONFLICT (content): Merge conflict in README
error: Failed to merge in the changes.
Patch failed at 0001 add-header
hint: Use 'git am --show-current-patch' to see the failed patch
Resolve all conflicts manually, mark them as resolved with
"git add/rm <conflicted_files>", then run "git rebase --continue".
You can instead skip this commit: run "git rebase --skip".
To abort and get back to the state before "git rebase", run "git rebase --abort".You'll still have to resolve the conflicts, but instead of resolving them in a merge commit, you'll be resolving them in your branch. Once you resolve them, your DAG will look like this:
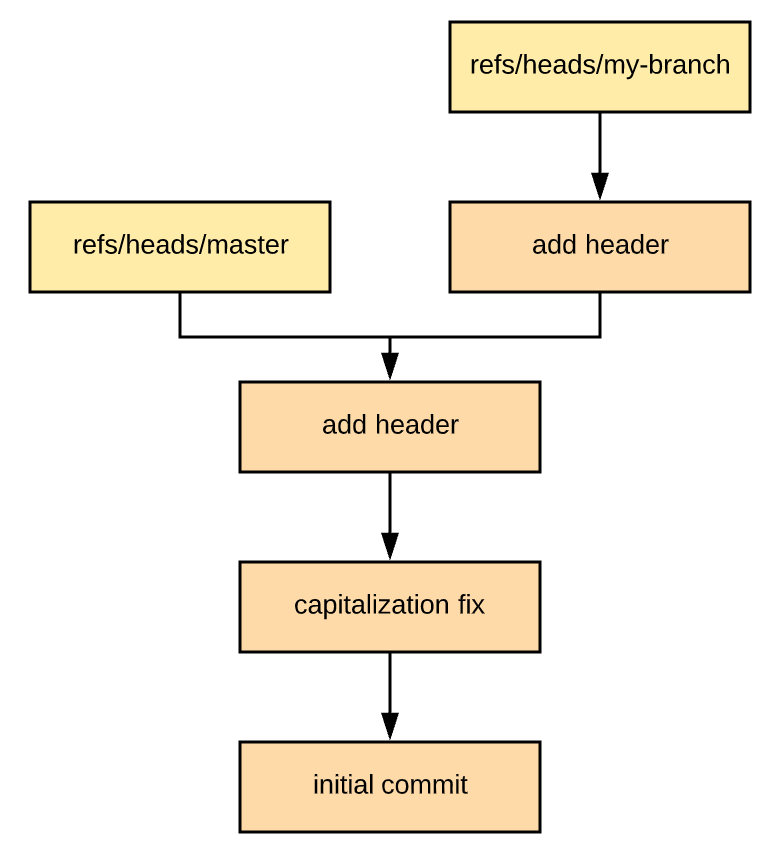
Merging my-branch into master is now a simple fast-forward merge.